Update 2014-11-26: so this old post hit the HN front page. Feel free to join the discussion over there: https://news.ycombinator.com/item?id=8661387.
If premature optimisation is the root of all evil, then timely optimisation is clearly the sum of all things good.
Over at ExtractBot, my HTML utility API, things have been hotting up gradually over several months; to the extent that, at peak, it’s now running across 18 c1.medium instances on Amazon EC2. Each of those weigh in at 1.7Gb memory and 5 compute units (2 cores x 2.5 units).
At standard EC2 rates that would work out at around $2.52/hr (almost $2000/mo).
Amazon states that one EC2 compute unit is the “equivalent CPU capacity of a 1.0-1.2 GHz 2007 Opteron or 2007 Xeon processor”. So that’s like having 90 of them churning through HTML; and it takes a lot of it to keep them busy.
It’s not so much the number of requests that dictates CPU load with ExtractBot, but more what the assemblies look like (think of an assembly as a factory conveyor belt of robots passing HTML snippets to each other). Now, most of our beta testers are fairly low volume right now, but one of them is a little different; over ~18 hours of each day they pump around 2.2M HTML pages into the system. In their specific assembly, each page runs through a single CSS robot and the results (~10 per page) then get fed into a further 11 separate CSS robots along with a couple of Regex robots.
If we look at just the CSS robots for now, that’s around 244 million over the course of the 18 hour run. Or to put it in a way that’s easier to visualise – over 3,700 per second.
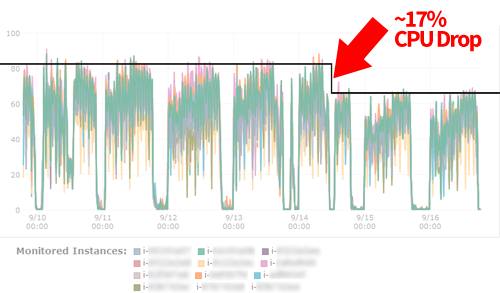
Normally, shaving 0.001s from a function would not exactly be top of my optimisation hit list, but after looking at where requests were spending most of their time it was obvious it would make considerable difference. 0.001s on 3.7k loops means we could save a whopping 3.7 seconds of CPU time in every second of real time. To put that another way, we could effectively drop about four of our c1.medium instances, a saving on standard EC2 pricing of over $400/mo.
So, what does shaving 0.001s from a single function look like?